Summary
Completely Automated Public Turing test to Tell Computers and Humans Apart (CAPTCHA) is a technique that attempts to differentiate between humans and machines on ability alone. Whether it's sensory, mobility, or cognitive ability, testing the user's ability will always create barriers that are insurmountable to some people, particularly when you consider than many people with sensory impairments rely on machines such as screen readers to overcome their sensory impairments.
What online services that attempt to protect their resources actually want to know isn't the ability of the person at the other end of the connection, but whether or not they are trustworthy. This article looks at social networking to see if the problem of trustworthiness can be solved without relying on the user's ability.
Author: Gez Lemon
Many thanks to Roberto Castaldo for providing an Italian version of this article.
Contents
Why CAPTCHA Fails
Websites that want to protect resources often use a CAPTCHA to prevent robots from abusing their services (see the Web Accessibility Initiative's report on the inaccessibility of CAPTCHA). They attempt to distinguish between humans and robots by testing for ability, such as requiring a human to be able to distinguish letters in a distorted image, or words from distorted sound files. The distortion is required because the robots that are used to try and break these defences have sophisticated algorithms, and often have better success than humans in deciphering them.
Multiple CAPTCHA Tests
Recognising that CAPTCHA has serious accessibility problems, some companies employ more than one method, such as a visual CAPTCHA and an auditory CAPTCHA. Although this solution is better than a single method of checking the user's ability, it fails to recognise that it's common for people to have more than one disability. For the elderly, it's extremely unlikely they will be able to use a service that determines humans from machines by sensory ability alone, as sensory abilities in humans diminish over time, but not in robots.
Some services might even go so far as to ask simple questions that are intended to be incredibly simple for humans, but difficult for a computer. An example might be, "what colour is an orange?" along with an edit box for the user to provide their answer. On the surface, this seems quite a reasonable approach, but free-format text does cause problems for people with cognitive disabilities, as well as visitors who aren't native speakers of the natural language of the web page. Questions that have to remain simple also have obvious patterns, and are relatively simple for a robot to crack.
Obscurity as a means of Defence
Another technique that is surprisingly popular is obscurity. Although obscurity could never be considered a serious defence against an online attack, these type of techniques usually receive a lot of attention because they appear to be successful at a glance, although their success is usually short lived if the technique gains enough attention, as by their very nature, they're incredibly simple to crack. Although these types of techniques are simple to crack, the services generally require the user to jump through all kinds of hoops in order to use the service.
If the service you are providing isn't in high demand, then obscurity will afford a limited amount of success. If someone wants to use your service, obscurity is about as effective as a saucepan made of chocolate.
Personally, I think developers that have looked into distinguishing humans from machines aren't asking the right questions. Realistically, they don't want to know what capabilities whoever or whatever has at the other end of the connection, but whether or not they are trustworthy. Testing for ability is not the same thing as testing trustworthiness, yet all a service attempting to protect its resources wants to know is whether or not they can trust whoever or whatever is at the other end of the connection. Unfortunately, trustworthiness is a difficult trait to test.
Social Networking Web Service
One possibility would be to use some kind of social networking web service that worked on an invitation only basis, based on the six degrees of separation theory . For example, an invitation-only service might reward points for people who have shown themselves to be trustworthy. Organisations that use the web service ping the service using the user's unique id (not attached to any personal data), and receive a calculated score of the user's trustworthiness based on the services that person has used. At first, the person may only have limited access to sites that don't afford much security, but in time, the user could become known as trustworthy online, which in turn allows them greater access to other online services. The User table might look as follows:
| Name | Type |
|---|---|
| UserID | Auto increment |
| ParentID | Integer |
| Trustworthiness | Integer |
| CanRecommend | Boolean |
Heuristics
As the system is based on recommendations, the system has a tree-like structure. If ever someone abuses that trust, they should become known as being untrustworthy. Being offered through an online service, this has the benefit of making this type of information available to everyone immediately. Anyone recommended by the person in question, along with the person who originally recommended them, should immediately be identified in the event of untrustworthy behaviour based on heuristics that could be determined from a history table. If someone in a branch is untrustworthy, everyone in that branch could have their ability to recommend removed up to a core level in the branch, which would ensure that people were particular about who they recommended, as there would be a penalty should they recommend someone who was unsociable. The UserHistory table might look as follows:
| Name | Type |
|---|---|
| HistoryID | Auto increment |
| UserID | Integer |
| Date | Date/Time |
| Notes | String |
| Trustworthiness | Integer |
| CanRecommend | Boolean |
Service Providers
The service would also need to include a list of organisations that provide online services that were eligible to provide feedback on people's performance to avoid malicious attacks to discredit people's trustworthiness. If a service provider reports someone of being unsociable, but that report is unfounded, then the service provider could continue to use the service, but wouldn't be able to report anti-social behaviour.
| Name | Type |
|---|---|
| ServiceID | Auto increment |
| Name String | Integer |
| CanReport | Boolean |
To help with heuristics, a Usage table would track users against services, which includes any reported incidents.
| Name | Type |
|---|---|
| UserID | Integer |
| ServiceID | Integer |
| Date | Date/Time |
| Incident | String |
Entity Relationship Diagram
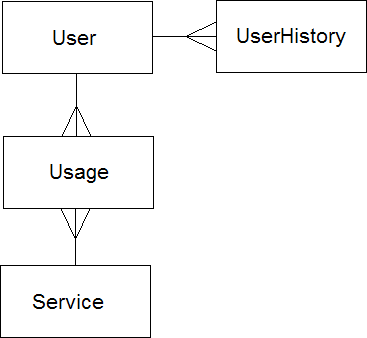
The User table relates to zero or more UserHistory records. Both the User table and the Service table relate to zero or more Usage records.
Conclusion
There would be a lot of work required to make this foolproof, and it would also take time to establish a trustworthy community, but I think using a web service based upon social networking is a far more reasonable approach than testing for a person's ability, whilst respecting the user's privacy online. Current CAPTCHA techniques test the user's ability, which will always cause insurmountable problems to some users; that cannot be ignored.
Category: Accessibility.
[accessibility-of-captcha.php#comment1]
Great article Gez.
I am curious about the contexts in which these social models will work and how flexible they are. For example, are there degrees of untrustworthiness?
Someone may be on the periphery of being untrustworthy, or have a bad reputation, either warranted or not, but may not be dangerous to the integrity of the network, would they be treated in the same way as a virus toting, hacking maniac?
I suppose these are ideas based on measuring the degree to which a contact is reliable. The CAPTCHA traditionally looks only at if someone is human, that is a very binary type approach (with two outcomes), is this a move towards a more measured qualitative model?
Posted by Joshue O Connor on
[accessibility-of-captcha.php#comment2]
Thanks for your comment, Josh.
That would depend on how a particular service wants to view someone on the periphery, and would probably vary from site to site. A personal blog might not be as suspicious as a bank, for example, and set the threshold a bit lower. If it turns out they're wrong, they can report the person and the trustworthiness will drop again. It's an excellent example of people being able to contribute to an online community, whilst protecting themselves and benefiting from others in the community at the same time.
I've suggested representing the trustworthiness of an individual as an integer so that the system is able to cater for the fact that trustworthiness should be measured in levels rather than having a binary nature. I also think the history table will be useful for heuristics to be able to come up with a calculated measure of trustworthiness, and it would be up to individual services how they want to consider that score, but there would obviously need to be some guidance on what the levels were.
This is a more qualitative model, but more than that, it's fundamentally a fairer model, as it makes no assumptions about the ability of the person at the other end of the connection. It's not even as if a CAPTCHA is that efficient, as machines have reasonable success with them, but they are known to be problematic to humans. The approach suggested here reflects the real world in that people earn respect - it isn't granted automatically.
Posted by Gez on
[accessibility-of-captcha.php#comment3]
Definitely interesting. I've thought this "friend of a friend" style thing could be a good way to make communities like eBay a bit safer.
Posted by pauldwaite on
[accessibility-of-captcha.php#comment4]
What Gez is suggesting; a community sponsored authentication mechanism with a flexible quantitative measure of trust; has already been done. The Thawte 'Web of Trust' was and indeed still is an attempt to build a self sustaining model of issuing personal digital certificates at minimal cost to the end user.
This approach has the concept of 'Notaries' which adds to the mutual authentication model trusted individuals who can 'independantly verify' an individual's claim to identity.
Technically it would not be difficult to implement a solution that used the Thawte certificates as a means to verify human input for forms and mail-in systems used by weblogs or bbs systems. How acceptable this mechanism would be to users is another question.
Relevant links
http://www.thawte.com/secure-email/web-of-trust-wot/index.html
Posted by Robert Campbell on
[accessibility-of-captcha.php#comment5]
The Thawte 'Web of Trust' has similarities to what I'm suggesting, but privacy is important in the model I'm suggesting. I'm not advocating people provide personal information to self-appointed trust police, with an option to pay someone to validate their personal details if all else fails.
Posted by Gez on
[accessibility-of-captcha.php#comment6]
Gez,
forgive me if I've misunderstood, but you held up CAPTCHAs as being inaccessible to people with disabilities and to elderly people and are proposing a scoring system instead, based on past perceived trustworthiness.
Isn't there a significant risk that a site which requires a high degree of trustworthiness is completely unusable to those people who don't spend enough online? i.e. people who are socially disadvantaged, the elderly and so on?
I've got no major technical problems with the model but I think this model requires people to be users of the internet who register for services instead of just browsing behaviour. You'd need a way of ensuring that people aren't seen as "less trustworthy" just because they don't use the internet much otherwise you're introducing another potentially discriminatory method.
BTW, The two minor technical issues are:
1) how do you prevent someone claiming to be someone else?
2) if someone receives a recommendation from someone bad, it doesn't necessarily mean they're bad - in effect the bad person should become a rel="nofollow" rather than marking down people who may be legitimate. Otherwise bad people could recommend good users just to get them blacklisted...!
Posted by JackP on
[accessibility-of-captcha.php#comment7]
Do you mean spend enough time, or enough money? I'm not suggesting people spend money at all. To build up a trustworthiness score would require people to have been online in the past, but wouldn't measure how much time they spend online, just ensure they do no damage in the time they have been online.
If someone never used a service, they probably wouldn't need this service. If they signed up for one service, and never abused that service, they would have a positive trustworthiness score that improved over time. Good behaviour is assumed and improves over time, and bad behaviour is penalised.
Without biometrics, no system can be absolutely sure that the person is who they claim to be. It would be down to individuals to protect their personal ID, and not give it to anyone else.
Yes, this is the difficult aspect of the whole system, which is why I associated this particular part with heuristics, rather than an out and out ban.
Posted by Gez on